Over the last couple months I spent parts of my (limited) spare time to learn more about compiler design and implementation. Converting a high-level program into executable code for a specific target (virtual) machine is a challenging and in my opinion very fascinating problem. I knew from the beginning that writing a complete compiler for a general-purpose programming language like C++ or C# would be interesting but ultimately too much work for a hobby project. Instead I decided to implement a (small) domain-specific language for 2D cutscenes. I’ve always been a big fan of SCUMM the scripting engine for Maniac Mansion, Monkey Island and the other LucasArts adventure games, so I wanted to work on something similar.
My goal for this project was to design a (very) simple language that can be used to create 2D actors (e.g. robots) which can be animated and moved around the scene. I also wanted to make it possible to show text for descriptions and actor conversations.
One of the revolutionary features of SCUMM was cooperative multi-threading, which made it possible to implement the behavior of different actors as a list of sequential commands or in other words each actor could execute its logic on a separate fiber. I really like this feature since it not only supports but emphasizes clean localized code and my goal was therefore to add support for co-routines to my cutscene language.
The script for a cutscene should be compiled into a (compact) byte-code representation which is then executed by a virtual machine (VM). It was important to me to use a (formal) grammar to define the language, so that it’s easy to verify whether or not a given script is valid.
Another goal was to make sure the compiler is very stable. It should be impossible to crash the compiler even when random data is entered. In fact I wanted to make sure that the compiler produces at least semi-helpful error messages if the script isn’t valid. Rather than “unable to compile script” the compiler should report something along the lines of “Syntax error: mismatched input ‘;’ expecting Digit (line 2 column 13)”.
I had a lot of fun working on this project and the following screenshot shows the current state of the “Cutscene Editor”. I achieved all of the goals mentioned above and I was even able to add a couple of extra features:
- Interactive editor provides instant feedback when writing cutscene scripts
- Disassembler converts a ‘executable’ into a cutscene script
- Cutscenes can be saved as an animated GIF
- Actor definitions (e.g. animation lists) are also defined by a (formal) grammar
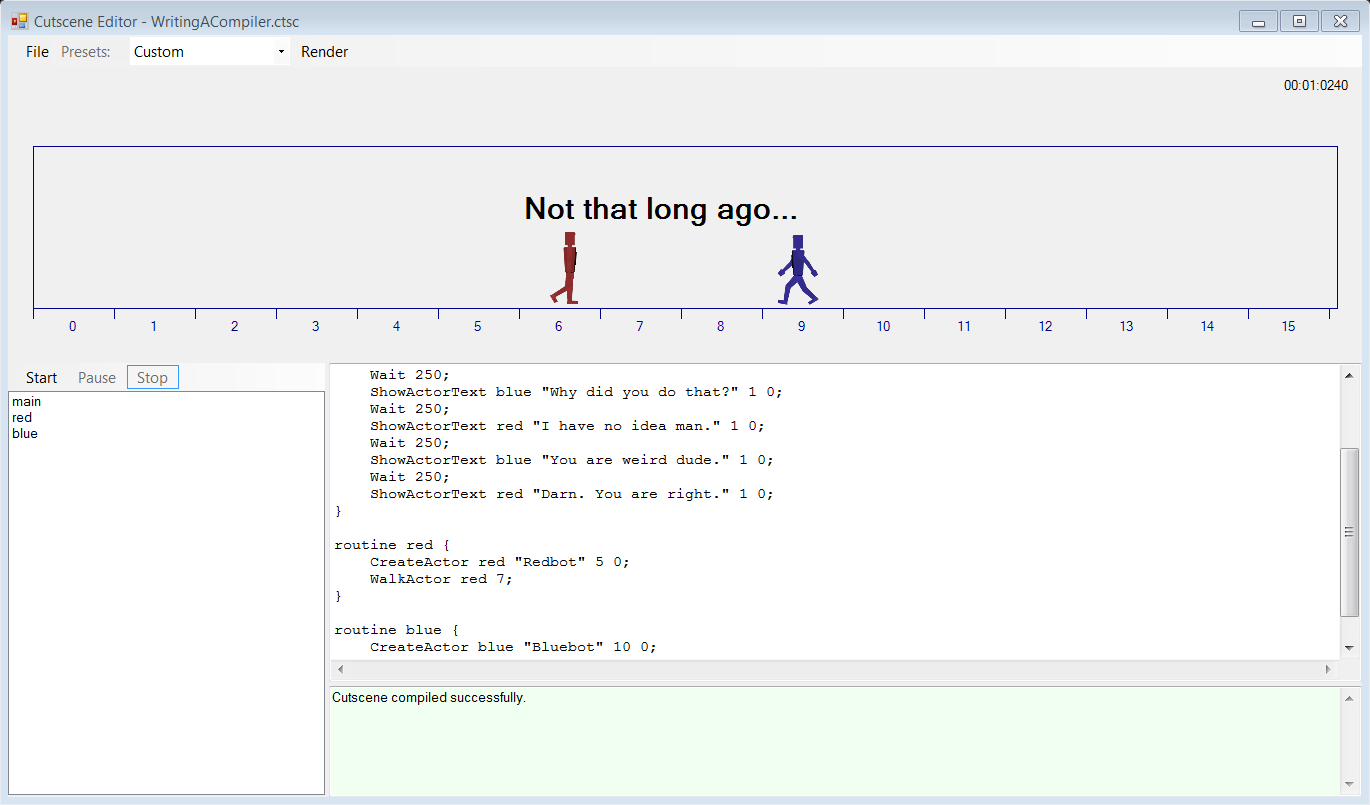
Cutscene Editor – Click to zoom.
I want to emphasize the fact that the goal of this project was NOT to create a full 2D scripting system that can be used for a real world project. There are a lot of missing features like variables, functions or math expressions. These concepts aren’t necessarily hard to implement, but I wanted to keep the scope of the compiler small so that A) the code is easy to read and understand and B) so I can actually finish this project.
You can download the “Cutscene Editor” here and try it out yourself. It was implemented using C#, so you’ll need Mono on a non-Window operating system to run it. I also decided to release the source-code for this project under the MIT license, so please feel free to modify or extend it at your heart’s content.
Write a grammar not a parser
The main job of a compiler is to convert a program written in human-friendly text form into a compact representation that can be executed efficiently by the target machine. In other words the compiler has to analyze the input code and identify all the statements (lexing, parsing) that should be executed and then convert them into an efficient sequence of commands (compiling) before generating an executable (linking).
My cutscene language is very simple which means that (lexing and) parsing a cutscene script is the most complicated step. Writing a parser isn’t difficult, but implementing a stable and efficient parser certainly is. To make things worse it’s also not the most interesting task and I would even go as far as to call it tedious work. Rather than writing lots of string splitting and searching code I decided to define my cutscene language using a grammar. Obviously I’d still need a parser in order to convert a cutscene script into byte-code though…
Thankfully this problem was easily solved by using a parser generator called ANTLR, which my good friend David Swift mentioned to me. ANTLR is a free meta-parser or in other words it parses a grammar in order to generate a parser for the given grammar. Even though it is implemented in Java it can produce parsers in various languages such as C#, Python and obviously Java. Since I wanted to use C# for this project anyway ANTLR turned out to be the perfect fit.
Defining my cutscene language using ANTLRs grammar was straight forward. You can see the full language specification below. This might look intimidating at first, especially if you aren’t used to working with grammars, but it’s actually pretty simple. The highlighted area contains the ‘important bits’ as it defines all the keyword for the language.

Cutscene grammar – Click to zoom.
I then used ANTLR to generate a C#-based parser for my cutscene language. ANTLR will automatically create an interface with handler methods for the keywords (and the rest of the grammar), so implementing a parser was as simple as implementing the interface. The following image shows the mapping between the grammar and (some of) the generated parser callback methods.

Grammar mapping – Click to zoom.
In addition to making it very convenient to parse cutscene scripts ANTLR also produces very helpful (syntax) errors if it provided cutsene isn’t valid. For example if a user forgets a semicolon ANTLR will generate a message describing the problem (missing ‘;’) and its location (line, column).
Generating the byte-code
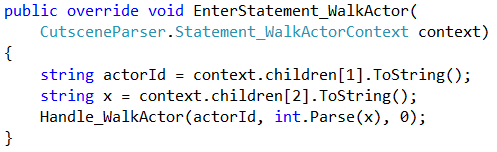
The byte-code generation (aka the compilation step) is easily implemented by extracting the arguments for the keywords from the context that is passed into the ANTLR-generated handler methods. For example the ‘WalkActor’ statement is compiled by extracting the name and the target location of the actor from the parsing-context before encoding this information in the byte-code of the current co-routine. The code below shows an example.
Once the byte-code for all co-routines is created the final executable is produced by combining the byte-code of all used co-routines into an executable. This so called linking step is very complicated for a general-purpose language like C++, but thankfully that isn’t the case for my simple cutscene language. In fact the most complicated aspect of the linking step is to compute the correct start address for ‘StartRoutine’ calls.
At this stage the compiler also makes sure that the script only uses actors that are created and a error will be printed if that isn’t the case. The linker doesn’t currently reason about the order of execution, so it is still possible to cause a run-time error by using an actor before it is created.
Executing the byte-code
Obviously the main goal of designing a domain-specific language and writing a compiler for it is to execute the generated byte-code. In the context of my simple cutscene language this is actually pretty easy to do. The interpreter (aka virtual machine) simply iterates over all active co-routines and executes its commands until either a yield, return or blocking operation is encountered.
Blocking operations won’t move the program counter (PC) until the command is completed. Most of these operations use local (per co-routine) registers to store the state of the command. For example the ‘Wait’ operation stores the elapsed time (in milliseconds) in register A. Once the value in the register is equal or larger to the specified wait duration the command is marked as completed and the PC is moved to the next operation.
As long as there is at least one co-routine that is still active the ‘renderer’ iterates of the current actors and draws their currently active animation frame along with all visible text instances. Once all co-routines encounter a return operation the cutscene has ended.
Conclusion
My takeaway from this project is that designing and implementing a simple domain-specific language is actually not that hard and certainly a lot of fun. Using ANTLR to generate the parser for the language has convinced me of the benefits of defining data formally using a grammar (or schema). I don’t even want to know how much time I spent writing parsers during my career.
I’ll probably never design and implement a programming language in my professional life (and I think that’s for the best), but I’ll certainly experiment with the idea of using a grammar to define asset files in the future. Hopefully I’ll never have to write another parser again!
Nice article! Fortunately there are lots of tools around that make your work easier.I had this core course back in university called Languages & Compilers where we had to write one and back then we used Lex which is a lexicographic analyzer and hooked that with YACC which is an LR generator just like the one you used.Only difference is our project back then was a language with functions,functors,ifs,loops,the whole shabang.
Another thing I remember though which might interest you was embedded languages.Basically you write a big header file and you rely a lot on macros which you then use to write code.We had recreated simple SQL code in the header and then wrote some SQL queries in a cpp file just like writing an SQL script and included the header file.Compiled it using the c++ compiler and it generated the result we wanted.Our professor had created such a beginner language which resembled pseudocode or early BASIC and back then used it as the language for our first programming course,as an intro to programming.
Ha cool! I want to play with that macro idea. 🙂
Yeah when I was in college we had to choose between graphics and compilers, so I missed out on it back then. I always wanted to learn more about it though. Very interesting stuff for sure.
Our college had the policy of teaching you a bit of everything so it was a core course.I can say the embedded language was fun at least when SQL was involved.So I guess small scripting languages or domain specific as you call them should work well like this and you only need C++ to make it.Dealing with the syntax is not going to be easy since you’re gonna need a clear picture of your entire domain before you can do anything more or at least if you want to make it as lightweight/optimized as possible.I think I might have that project somewhere.I can upload it to my website if you’d like.